
La arquitectura BERT#
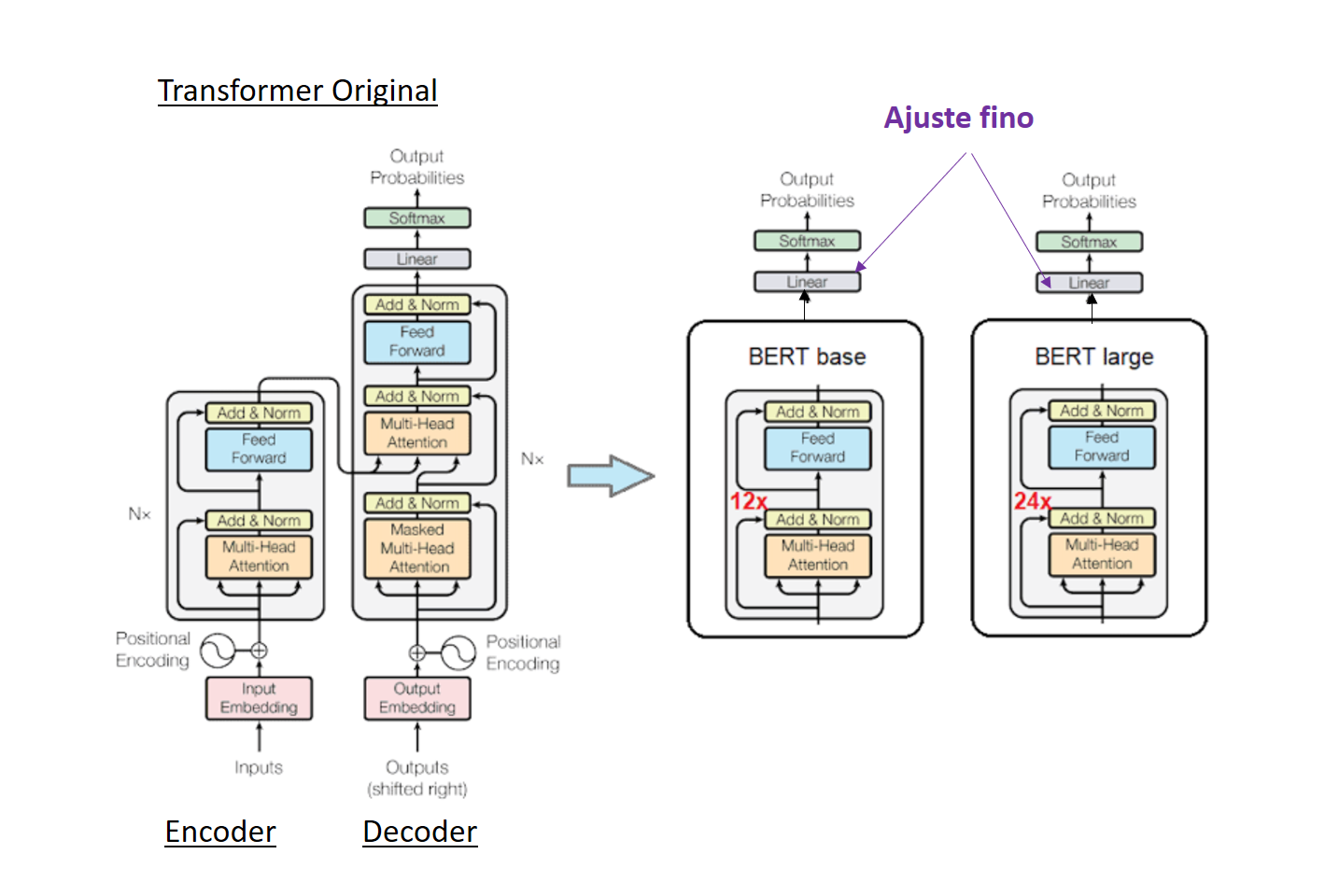
La arquitectura BERT (Bidirectional Encoder Representations from Transformers) sólo usa el encoder del Transformer, eliminando la pila de decodificación [Rothman, 2022].
El modelo BERT original se lanzó poco después del Generative Pre-trained Transformer (GPT) de OpenAI, y ambos se basaron en el trabajo de la arquitectura Transformer propuesto el año anterior. Mientras que GPT se centró en la generación de lenguaje natural (NLG), BERT priorizó la comprensión del lenguaje natural (NLU).
Arquitecturas de sólo codificador (encoder)#
El Transformer en 2017 inició una carrera para producir nuevos modelos que se basaran en su diseño innovador. OpenAI en junio de 2018, crea GPT: un modelo de solo decodificador que sobresalió en NLG, y finalmente pasó a impulsar ChatGPT en iteraciones posteriores. Google lanza BERT cuatro meses después: un modelo de solo codificador diseñado para NLU. Ambas arquitecturas pueden producir modelos muy capaces, pero las tareas que pueden realizar son ligeramente diferentes. A continuación se ofrece una descripción general de cada arquitectura.
Objetivo : hacer predicciones sobre palabras dentro de una secuencia de entrada.
Visión general : aceptar una secuencia de entrada y crear representaciones vectoriales numéricas enriquecidas para cada token. No tienen el decodificador que generan nuevas palabras como un chatbot, usan pilas de codificadores o encoders. Están orientados a reconocimiento de entidades con nombre (NER) o análisis de sentimientos. Las representaciones vectoriales enriquecidas creadas por los bloques del codificador son las que le dan a BERT una comprensión profunda del texto de entrada.
Nota : Es técnicamente posible generar texto con BERT, pero como veremos, esto no es para lo que se pretendía la arquitectura, y los resultados no rivalizan de ninguna manera con los modelos de solo decodificador
Arquitecturas de sólo decodificador (decoder)#
Objetivo : Predecir una nueva secuencia de salida en respuesta a una secuencia de entrada.
Visión general : omitien el bloque de codificador por completo y apilan varios decodificadores o decoders juntos en un solo modelo. Estos modelos aceptan mensajes como entradas y generan respuestas mediante la predicción de la siguiente token, uno a la vez, en una tarea conocida como Next Token Prediction (NTP).
Nota : los más conocidos por el público en general debido al uso generalizado de ChatGPT, que funciona con modelos de solo decodificador (GPT-3.5 y GPT-4)
En entrenamiento previo#
GPT también popularizó el entrenamiento previo del modelo. El entrenamiento previo implica entrenar un modelo grande para adquirir una comprensión amplia del lenguaje (que abarca aspectos como el uso de palabras y los patrones gramaticales) con el fin de producir un modelo fundamental independiente de la tarea.
El ajuste fino implica modificar sólo las capas finales que aparecen como lineales (en color morado en el gráfico siguiente), dejando el resto de pesos sin alterar.
Dependiendo de la tarea, el cabezal de clasificación (capa lineal en morado) se puede cambiar para que contenga un número diferente de neuronas de salida. Para una tarea de clasificación multiclase con 10 clases, la cabeza se puede cambiar para que tenga 10 neuronas en la capa de salida.
El contexto bidireccional#
BERT predice la probabilidad de observar ciertas palabras dado que se han observado palabras anteriores. Esto es algo genérico en todos los modelos de lenguaje. GPT está entrenado para predecir la siguiente palabra más probable en una secuencia.
La bidireccionalidad es quizás la característica más significativa de BERT, esto es algo que deriva de usar sólo el codificador (que por naturaleza es bidireccional) y descartar el decodificador (que por naturaleza es unidireccional).
Bidireccional denota que cada palabra en la secuencia de entrada puede obtener contexto de las palabras anteriores y posteriores (denominadas contexto izquierdo y contexto derecho, respectivamente). En términos técnicos, decimos que el mecanismo de atención puede atender a los tokens anteriores y posteriores de cada palabra.
Un |
hombre |
estaba |
[MASK] |
en |
la |
orilla |
de |
un |
río |
|---|---|---|---|---|---|---|---|---|---|
\(\leftarrow\) |
\(\leftarrow\) |
\(\leftarrow\) |
\(\rightarrow\) |
\(\rightarrow\) |
\(\rightarrow\) |
\(\rightarrow\) |
\(\rightarrow\) |
\(\rightarrow\) |
Para BERT, la tarea aquí es predecir la palabra enmascarada indicada por [MASK], dado que esta palabra tiene palabras tanto a la izquierda como a la derecha, las palabras de ambos lados se pueden usar para proporcionar contexto.
Como modelo bidireccional, BERT adolece de dos grandes inconvenientes:
Aumento del tiempo de entrenamiento.
Bajo rendimiento en la generación de idiomas: es más adecuado para tareas como análisis de sentimientos.
Pre-entrenamiento de un modelo BERT#
El entrenamiento de un modelo bidireccional requiere tareas que permitan usar tanto el contexto izquierdo como el derecho para realizar predicciones. A tal fin diseñaron dos tareas:
La tarea de Modelo de Lenguaje Enmascarado (MLM, Masked Language Modeling): El modelo debe entrenarse para usar el contexto izquierdo y el contexto derecho de una secuencia de entrada para realizar una predicción. Esto se logra enmascarando aleatoriamente el 15% de las palabras en los datos de entrenamiento y entrenando a BERT para predecir la palabra que falta. Esta tarea ya existía en linguística y se conocía como tarea de Cloze ([Taylor, 1953]), aunque por la popularidad de BERT se conoce como tarea MLM.
The cat sat on it because it was a nice rug.
The cat sat on it [MASK] it was a nice rug.
BERT tomará una secuencia de entrada de un máximo de 512 tokens tanto para BERT Base como para BERT Large. Si se encuentran menos del número máximo de tokens en la secuencia, se agregará relleno mediante tokens para alcanzar el recuento máximo de 512.
El número de tokens de salida también será exactamente igual al número de tokens de entrada. Si existe un token enmascarado en la posición \(i\) en la secuencia de entrada, la predicción de BERT se encontrará en la posición \(i\) en la secuencia de salida.
El error se calcula utilizando una función de pérdida, que suele ser la función de pérdida de entropía cruzada en las posiciones \(i\) donde se encuentren los token enmascarados
La tarea de Predicción de Siguiente Oración (NSP, Next Sentence Predict): el objetivo es clasificar si un segmento (generalmente una oración) sigue lógicamente a otro. Al pre-entrenarse para NSP, BERT es capaz de desarrollar una comprensión del flujo entre oraciones en texto en prosa, una habilidad que es útil para una amplia gama de problemas de NLU, tales como: Pares de oraciones en paráfrasis, Pares hipótesis-premisa en implicación, Pares de preguntas y pasajes en las respuestas a preguntas.
La entrada para NSP consta del primer y segundo segmento (denotados A y B) separados por un token con un segundo token al final. En realidad, BERT espera que al menos un token por secuencia de entrada denote el final de la secuencia, independientemente de si se está realizando NSP o no
Los datos de entrenamiento se pueden generar fácilmente a partir de cualquier corpus monolingüe seleccionando oraciones con su siguiente oración el 50% de las veces y una oración aleatoria para el 50% restante de las oraciones.
Incrustaciones en un modelo BERT#
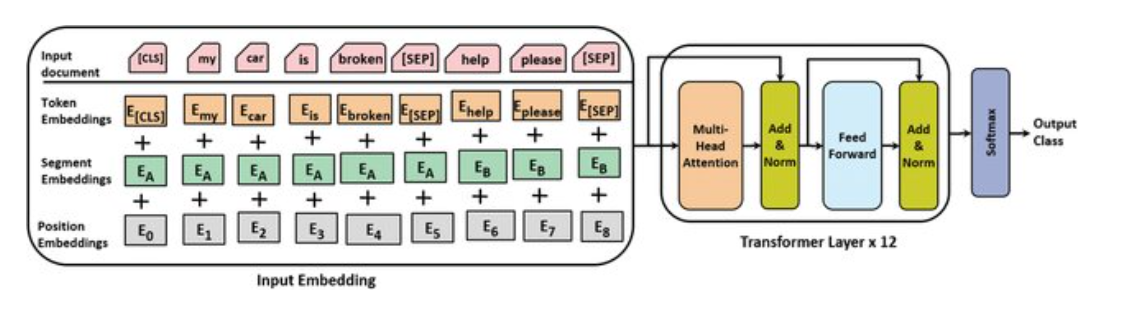
La incrustación que entra al transformer es suma la incrustación del token, más la de segmento (sentencia, frase, palabra) y la codificación posicional.
La incrustación de token es aprendida para cada token, igual que en el modelo Transformer.
La incrustación por segmento se utilizan para distinguir las oraciones dentro de un par de oraciones, como en tareas de clasificación de relaciones entre frases. BERT acepta una secuencia de hasta dos oraciones, A y B. A cada token se le asigna una etiqueta de segmento, usando valores \(0\) y \(1\):
[CLS] |
La |
casa |
es |
grande |
[SEP] |
El |
perro |
duerme |
[SEP] |
|---|---|---|---|---|---|---|---|---|---|
\(\downarrow\) |
\(\downarrow\) |
\(\downarrow\) |
\(\downarrow\) |
\(\downarrow\) |
\(\downarrow\) |
\(\downarrow\) |
\(\downarrow\) |
\(\downarrow\) |
\(\downarrow\) |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
La incrustación posicional captura la posición del token en la secuencia para permitir que el modelo entienda el orden de las palabras. A diferencia del Transformer, las codificaciones posicionales en BERT son fijas y no son generadas por una función de senos y cosenos. Esto significa que BERT está restringido a 512 tokens en su secuencia de entrada tanto para BERT Base como para BERT Large. Ya se ha comentado que las secuencias en BERT tienen un máximo de 512 tokens.
Token especiales en BERT#
Como se ve en el gráfico anterior BERT tiene algunos token especiales:
[PAD] : Token de relleno para completar las secuencias hasta 512, cuando son más cortas.
[UNK] : Token desconocido, cuando no está en el vocabulario.
[CLS] : Token de clasifiación, se espera al principio de cada secuencia.
[SEP] : Token separador, separa dos segmentos de una sóla secuencia.
[MASK] : Token de máscara, se usa para entrenar a BERT.
Dimensiones usadas en la arquitectura BERT#
En el Transformer original las dimensiones son \(d_{model}=512\) y el número de cabeceras es \(A=8\), quedando \(d_k=512/8=64\).
Mientras que el BERT base \(d_{model}=768\) y el número de cabeceras es \(A=12\), quedando \(d_k=768/12=64\).
Y el BERT large \(d_{model}=1024\) y el número de cabeceras es \(A=16\), quedando \(d_k=1024/16=64\).
Ambas versiones de BERT también difieren en algunas características en cuanto número de capas y número de neuronas en las capas de paso adelante

Ajuste Fino#
El pre-entrenamiento es el primer paso en el marco de trabajo BERT que tiene 2 sub-etapas:
Definir el modelo de arquitectura: número de capas, de cabeceras, dimensiones y otros bloques del modelo.
Entrenar el modelo en las tareas MLM y NSP
El segundo paso es el ajuste fino que se puede descomponer en dos etapas:
Descargar un modelo elegido con los parámetros BERT preentrenados.
Realizar un ajuste fino de los parámetros para algunas tareas tales como Recognizing Textual Entailment (RTE) y Situations With Adversarial Generations (SWAG)
A continuación se muestras los pasos necesarios para un ajuste fino de un modelo pre-entrenado
Se importan librerías#
import torch
import torch.nn as nn
from torch.utils.data import TensorDataset, DataLoader, RandomSampler, SequentialSampler
from sklearn.model_selection import train_test_split
from transformers import BertTokenizer, BertConfig
from transformers import BertForSequenceClassification, get_linear_schedule_with_warmup
from tqdm import tqdm, trange #for progress bars
import pandas as pd
import io
import numpy as np
import matplotlib.pyplot as plt
from IPython.display import Image #for image rendering
ajusteFino = False # Poner la variable a True para activar el ajuste fino del modelo
Carga de Datos#
Se usará un conjunto de datos de análisis de sentimiento proporcionado por la Universidad de Stanford. Este conjunto de datos contiene 50.000 reseñas de películas en línea de Internet Movie Database (IMDb), y cada reseña está etiquetada como o .
Se puede descargar el dato original directamente desde el vínculo:
https://ai.stanford.edu/~amaas/data/sentiment/
Pero vamos a trabajar con la versión CSV que es posible descargar desde:
https://www.kaggle.com/datasets/lakshmi25npathi/imdb-dataset-of-50k-movie-reviews?resource=download
El archivo IMDB Dataset.csv tiene la columna review con el texto de la revisiones y se encuentra cada revisión anotada como positive o negative
import pandas as pd
df = pd.read_csv('./data/IMDB Dataset.csv')
df.head()
| review | sentiment | |
|---|---|---|
| 0 | One of the other reviewers has mentioned that ... | positive |
| 1 | A wonderful little production. <br /><br />The... | positive |
| 2 | I thought this was a wonderful way to spend ti... | positive |
| 3 | Basically there's a family where a little boy ... | negative |
| 4 | Petter Mattei's "Love in the Time of Money" is... | positive |
Depuración de los datos#
Eliminar algunas etiquetas y los espacios en blanco innecesarios
# Remove the break tags (<br />)
df['review_cleaned'] = df['review'].apply(lambda x: x.replace('<br />', ''))
# Remove unnecessary whitespace
#df['review_cleaned'] = df['review_cleaned'].replace('\s+', ' ', regex=True)
df['review_cleaned'] = [x.strip() for x in df['review_cleaned'] if isinstance(x, str)]
# Compare 72 characters of the second review before and after cleaning
print('Before cleaning:')
print(df.iloc[1]['review'][0:100])
print('\nAfter cleaning:')
print(df.iloc[1]['review_cleaned'][0:100])
Before cleaning:
A wonderful little production. <br /><br />The filming technique is very unassuming- very old-time-B
After cleaning:
A wonderful little production. The filming technique is very unassuming- very old-time-BBC fashion a
Y se codifica la columna de sentimientos#
df['sentiment_encoded'] = df['sentiment'].\
apply(lambda x: 0 if x == 'negative' else 1)
df.head()
| review | sentiment | review_cleaned | sentiment_encoded | |
|---|---|---|---|---|
| 0 | One of the other reviewers has mentioned that ... | positive | One of the other reviewers has mentioned that ... | 1 |
| 1 | A wonderful little production. <br /><br />The... | positive | A wonderful little production. The filming tec... | 1 |
| 2 | I thought this was a wonderful way to spend ti... | positive | I thought this was a wonderful way to spend ti... | 1 |
| 3 | Basically there's a family where a little boy ... | negative | Basically there's a family where a little boy ... | 0 |
| 4 | Petter Mattei's "Love in the Time of Money" is... | positive | Petter Mattei's "Love in the Time of Money" is... | 1 |
Tokenizar los datos de ajuste fino#
Divide el texto de la revisión en tokens individuales, agrega los tokens especiales y controla el relleno. Es importante seleccionar el tokenizador adecuado para el modelo.
Se usará un tokenizador previamente entrenado del repositorio del modelo. Hay cuatro opciones principales cuando se trabaja con BERT, cada una de las cuales utiliza el vocabulario de los tokenizadores preentrenados de Google:
bert-base-uncased : el vocabulario de la versión más pequeña de BERT, que NO distingue entre mayúsculas y minúsculas.
bert-base-cased : el vocabulario de la versión más pequeña de BERT, que distingue entre mayúsculas y minúsculas.
bert-large-uncased : el vocabulario de la versión larga de BERT, que NO distingue entre mayúsculas y minúsculas.
bert-large-cased : el vocabulario de la versión larga de BERT, que distingue entre mayúsculas y minúsculas.
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
print(tokenizer)
BertTokenizer(name_or_path='bert-base-uncased', vocab_size=30522, model_max_length=512, is_fast=False, padding_side='right', truncation_side='right', special_tokens={'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'}, clean_up_tokenization_spaces=True, added_tokens_decoder={
0: AddedToken("[PAD]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100: AddedToken("[UNK]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
101: AddedToken("[CLS]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
102: AddedToken("[SEP]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
103: AddedToken("[MASK]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
}
)
Proceso de codificación: conversión de texto en tokens a ID de token#
Se utiliza la función encode_plus que devuelve un diccionario con los siguientes campos:
input_ids : IDs de los tokens. Es el mismo valor que devuelve la función: input_ids.
token_type_ids : Da un valor 0 para la oración A y un valor 1 para la oración B.
attention_mask : Una lista de 0 y 1 donde 0 indica que un token debe ser ignorado durante el proceso de atención y 1 indica que un token no debe ser ignorado.
token_ids = []
attention_masks = []
# Encode each review
for i in range(df['review_cleaned'].values.shape[0]): # Opción para generar HTML con jupyter-book
#for i in tqdm(range(df['review_cleaned'].values.shape[0])): # Opción para usuario con barra de progreso
batch_encoder = tokenizer.encode_plus(
df['review_cleaned'].values[i],
max_length = 512,
padding = 'max_length',
truncation = True,
return_tensors = 'pt')
token_ids.append(batch_encoder['input_ids'])
attention_masks.append(batch_encoder['attention_mask'])
# Convert token IDs and attention mask lists to PyTorch tensors
token_ids = torch.cat(token_ids, dim=0)
attention_masks = torch.cat(attention_masks, dim=0)
labels = torch.tensor(df['sentiment_encoded'].values)
token_ids[0][0:10]
tensor([ 101, 2028, 1997, 1996, 2060, 15814, 2038, 3855, 2008, 2044])
Se truncan los datos en el caso de no disponer aceleración CUDA#
Simplemente para hacer una prueba de concepto
if not torch.cuda.is_available():
token_ids = token_ids[0:100]
attention_masks = attention_masks[0:100]
labels = labels[0:100]
Dividir los datos en entrenamiento y validación y crear los conjuntos de datos (datasets) y cargadores (dataloaders)#
val_size = 0.1
# Split the token IDs
train_ids, val_ids = train_test_split(
token_ids,
test_size=val_size,
shuffle=False)
# Split the attention masks
train_masks, val_masks = train_test_split(
attention_masks,
test_size=val_size,
shuffle=False)
# Split the labels
train_labels, val_labels = train_test_split(
labels,
test_size=val_size,
shuffle=False)
# Create the DataLoaders
train_data = TensorDataset(train_ids, train_masks, train_labels)
train_dataloader = DataLoader(train_data, shuffle=True, batch_size=16)
val_data = TensorDataset(val_ids, val_masks, val_labels)
val_dataloader = DataLoader(val_data, batch_size=16)
Modelo BERT#
Configuración del modelo BERT#
El siguiente paso es cargar un modelo BERT previamente entrenado para ajustarlo. Se puede importar un modelo desde el repositorio de modelos de Hugging Face de manera similar a como se hizo con el tokenizador. Hugging Face tiene muchas versiones de BERT con cabezales de clasificación ya adjuntos, lo que hace que este proceso sea muy conveniente. Estos son algunos ejemplos de modelos con cabezales de clasificación preconfigurados:
BertForMaskedLM
BertForNextSentencePrediction
BertForSequenceClassification
BertForMultipleChoice
BertForTokenClassification
BertForQuestionAnswering
Por supuesto, es posible importar un modelo BERT sin cabeza y crear su propio cabezal de clasificación desde cero en PyTorch o Tensorflow.
Se utiliza el modelo pre-entrenado y con la salida adapatada a un clasificador (BertForSequenceClassification) indicando en el número de clases a identificar como 2
from transformers import BertForSequenceClassification
model = BertForSequenceClassification.from_pretrained(
'bert-base-uncased',
num_labels=2)
configuration = model.config
configuration
Some weights of BertForSequenceClassification were not initialized from the model checkpoint at bert-base-uncased and are newly initialized: ['classifier.bias', 'classifier.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
BertConfig {
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"classifier_dropout": null,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"position_embedding_type": "absolute",
"torch_dtype": "float32",
"transformers_version": "4.53.0",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 30522
}
Optimizador, función de pérdida y programador#
Se requiere un optimizador para calcular los cambios necesarios en cada peso y sesgo. El habitual es AdamW.
Los modelos de lenguaje suelen utilizar la función de pérdida de entropía cruzada.
Los programadores (scheduler) están diseñados para disminuir gradualmente la tasa de aprendizaje a medida que continúa el proceso de entrenamiento, reduciendo el tamaño de los cambios realizados en cada peso y el sesgo en cada paso del optimizador.
EPOCHS = 1
# Optimizer
#optimizer = torch.optim.AdamW(optimizer_grouped_parameters, lr=2e-5, eps = 1e-8 )
optimizer = torch.optim.AdamW(model.parameters())
# Loss function
loss_function = nn.CrossEntropyLoss()
# Scheduler
num_training_steps = EPOCHS * len(train_dataloader)
scheduler = get_linear_schedule_with_warmup(
optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps)
Bucle con el ajuste fino#
Por la carga del proceso se necesita utilizar GPU o entorno CUDA.
En CPU se lanza sólo una ejecución truncada para hacer una prueba de concepto. Lógicamente la precisión es muy inferior a la que se puede alcanzar incrementando el número de elementos del dataset y las épocas de entrenamiento.
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
device
device(type='cpu')
if ajusteFino:
for epoch in range(0, EPOCHS):
model.train()
training_loss = 0
for batch in tqdm(train_dataloader, desc="Época=" + str(epoch)):
batch_token_ids = batch[0].to(device)
batch_attention_mask = batch[1].to(device)
batch_labels = batch[2].to(device)
model.zero_grad()
loss, logits = model(
batch_token_ids,
token_type_ids = None,
attention_mask=batch_attention_mask,
labels=batch_labels,
return_dict=False)
training_loss += loss.item()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
scheduler.step()
average_train_loss = training_loss / len(train_dataloader)
filename = "data/analisis_sentimientos.pt"
torch.save(model.state_dict(), filename)
print("Proceso de ajuste fino finalizado. average_train_loss=", average_train_loss)
else:
print("El ajuste fino no está activo. Se recupera un modelo previamente entrenado almacenado en analisis_sentimientos.pt")
filename = "data/analisis_sentimientos.pt"
model.load_state_dict(torch.load(filename, map_location=torch.device(device)))
Show code cell output
El ajuste fino no está activo. Se recupera un modelo previamente entrenado almacenado en analisis_sentimientos.pt
Validación contra el conjunto de validación#
def calculate_accuracy(preds, labels):
""" Calculate the accuracy of model predictions against true labels.
Parameters:
preds (np.array): The predicted label from the model
labels (np.array): The true label
Returns:
accuracy (float): The accuracy as a percentage of the correct
predictions.
"""
pred_flat = np.argmax(preds, axis=1).flatten()
labels_flat = labels.flatten()
accuracy = np.sum(pred_flat == labels_flat) / len(labels_flat)
return accuracy
model.eval()
val_loss = 0
val_accuracy = 0
for batch in tqdm(val_dataloader):
batch_token_ids = batch[0].to(device)
batch_attention_mask = batch[1].to(device)
batch_labels = batch[2].to(device)
with torch.no_grad():
(loss, logits) = model(
batch_token_ids,
attention_mask = batch_attention_mask,
labels = batch_labels,
token_type_ids = None,
return_dict=False)
logits = logits.detach().cpu().numpy()
label_ids = batch_labels.to('cpu').numpy()
val_loss += loss.item()
val_accuracy += calculate_accuracy(logits, label_ids)
average_val_accuracy = val_accuracy / len(val_dataloader)
Show code cell output
0%| | 0/1 [00:00<?, ?it/s]
100%|████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:15<00:00, 15.13s/it]
100%|████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:15<00:00, 15.13s/it]
average_val_accuracy
np.float64(0.5)